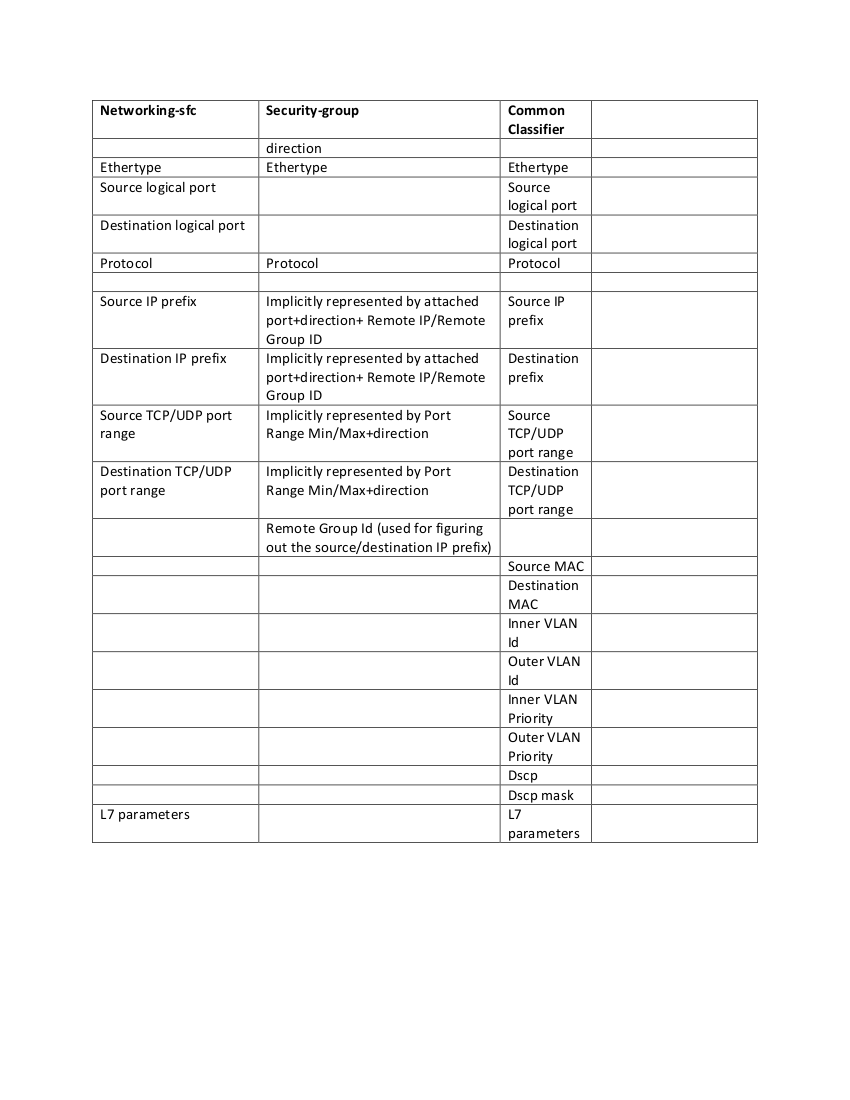
Hi community and common classifier team, In anticipation to the next common classifier meeting, I've added a meeting agenda item to the next meeting's agenda [1] about the proposed "typed classifications" model for the new common classifier. The typed classifications model is described in [2, comment #26] and essentially separates classification matches into different classification types, instead of grouping all kinds of different classifications into a single monolithic structure such as [3]. This kind of model is actually not new, as neutron-classifier was already following such a path [4]. Can someone give feedback on the described model and how neutron-classifier is planned to be reused for the new effort? [1] https://wiki.openstack.org/wiki/Neutron/CommonFlowClassifier [2] https://bugs.launchpad.net/neutron/+bug/1476527 [3] https://wiki.openstack.org/w/images/c/c8/Neutron_Common_Classifier.png [4] https://github.com/openstack/neutron-classifier/blob/10b2eb3127f4809e52e3cf1627c34228bca80101/neutron_classifier/common/constants.py#L17 Best regards, Igor. -------------- next part -------------- An HTML attachment was scrubbed... URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20160610/995b876b/attachment.html>
{kind=link}