[openstack-dev] [TripleO] TripleO/Ansible PTG session
Giulio Fidente
gfidente at redhat.com
Tue Sep 19 14:37:25 UTC 2017
On 09/18/2017 05:37 PM, James Slagle wrote:
> On Wednesday at the PTG, TripleO held a session around our current use
> of Ansible and how to move forward. I'll summarize the results of the
> session. Feel free to add anything I forgot and provide any feedback
> or questions.
thanks for starting this!
> We discussed the existing uses of Ansible in TripleO and how they
> differ in terms of what they do and how they interact with Ansible. I
> covered this in a previous email[1], so I'll skip over summarizing
> those points again.
>
> I explained a bit about the "openstack overcloud config download"
> approach implemented in Pike by the upgrades squad. This method
> no-op's out the deployment steps during the actual Heat stack-update,
> then uses the cli to query stack outputs to create actual Ansible
> playbooks from those output values. The Undercloud is then used as the
> Ansible runner to apply the playbooks to each Overcloud node.
>
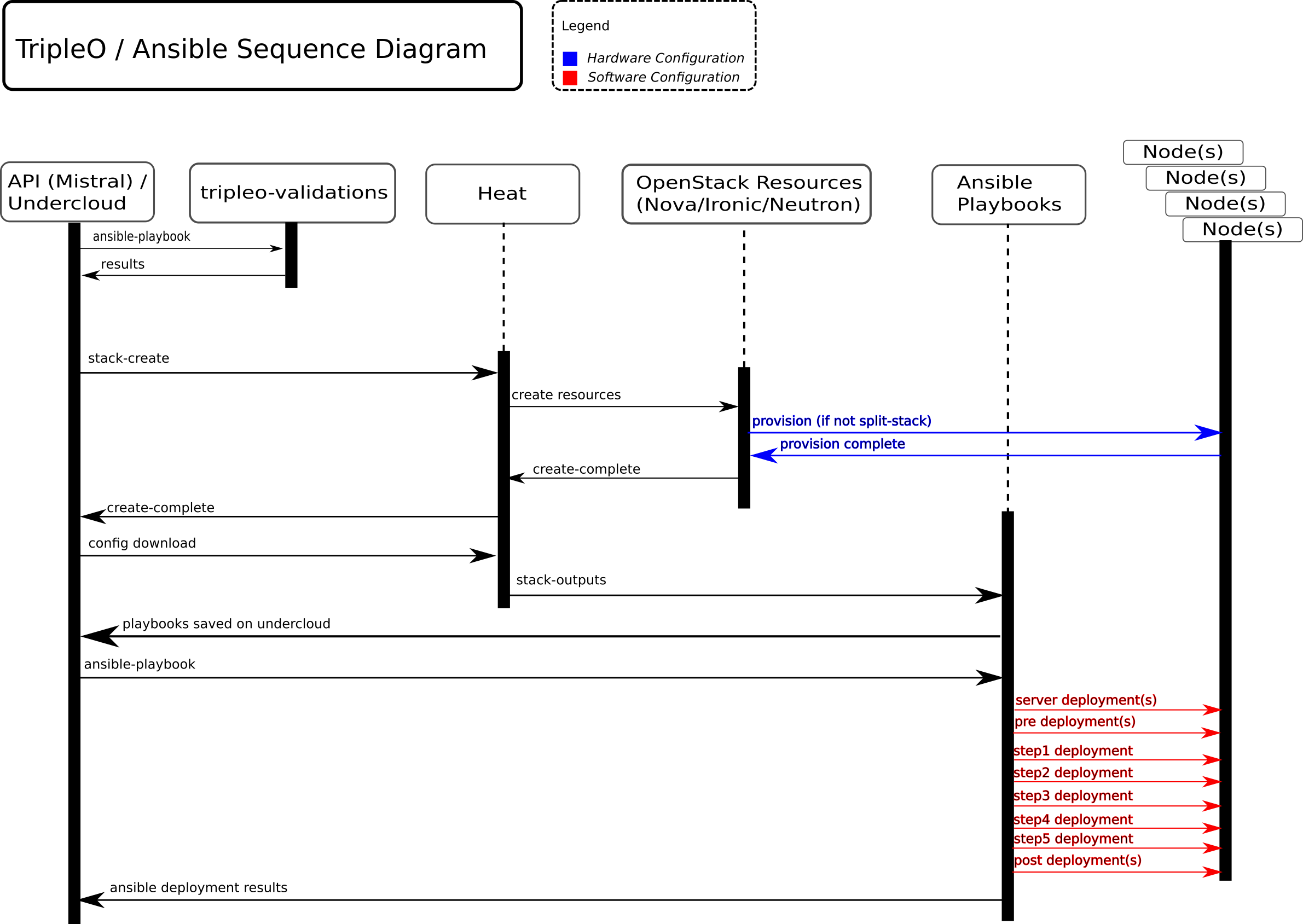
> I created a sequence diagram for this method and explained how it
> would also work for initial stack deployment[2]:
>
> https://slagle.fedorapeople.org/tripleo-ansible-arch.png
>
> The high level proposal was to move in a direction where we'd use the
> config download method for all Heat driven stack operations
> (stack-create and stack-update).
>
> We highlighted and discussed several key points about the method shown
> in the diagram:
>
> - The entire sequence and flow is driven via Mistral on the Undercloud
> by default. This preserves the API layer and provides a clean reusable
> interface for the CLI and GUI.
I think it's worth saying that we want to move the deployment steps out
of heat and in ansible, not in mistral so that mistral will run the
workflow only once and let ansible go through the steps
I think having the steps in mistral would be a nice option to be able to
rerun easily a particular deployment step from the GUI, versus having
them in ansible which is instead a better option for CLI users ... but
it looks like having them in ansible is the only option which permits us
to reuse the same code to deploy an undercloud because having the steps
in mistral would require the undercloud installation itself to depend on
mistral which we don't want to
James, Dan, please comment on the above if I am wrong
> - It would still be possible to run ansible-playbook directly for
> various use cases (dev/test/POC/demos). This preserves the quick
> iteration via Ansible that is often desired.
>
> - The remaining SoftwareDeployment resources in tripleo-heat-templates
> need to be supported by config download so that the entire
> configuration can be driven with Ansible, not just the deployment
> steps. The success criteria for this point would be to illustrate
> using an image that does not contain a running os-collect-config.
>
> - The ceph-ansible implementation done in Pike could be reworked to
> use this model. "config download" could generate playbooks that have
> hooks for calling external playbooks, or those hooks could be
> represented in the templates directly. The result would be the same
> either way though in that Heat would no longer be triggering a
> separate Mistral workflow just for ceph-ansible.
I'd say for ceph-ansible, kubernetes and in general anything else which
needs to run with a standard playbook installed on the undercloud and
not one generated via the heat templates... these "external" services
usually require the inventory file to be in different format, to
describe the hosts to use on a per-service basis, not per-role (and I
mean tripleo roles here, not ansible roles obviously)
About that, we discussed a more long term vision where the playbooks
(static data) needd to describe how to deploy/upgrade a given service is
in a separate repo (like tripleo-apb) and we "compose" from heat the
list of playbooks to be executed based on the roles/enabled services; in
this scenario we'd be much closer to what we had to do for ceph-ansible
and I feel like that might finally allow us merge back the ceph
deployment (or kubernetes deployment) process into the more general
approach driven by tripleo
James, Dan, comments?
> - We will need some centralized log storage for the ansible-playbook
> results and should consider using ARA.
>
> As it would be a lot of work to eventually make this method the
> default, I don't expect or plan that we will complete all this work in
> Queens. We can however start moving in this direction.
>
> Specifically, I hope to soon add support to config download for the
> rest of the SoftwareDeployment resources in tripleo-heat-templates as
> that will greatly simplify the undercloud container installer. Doing
> so will illustrate using the ephemeral heat-all process as simply a
> means for generating ansible playbooks.
>
> I plan to create blueprints this week for Queens and beyond. If you're
> interested in this work, please let me know. I'm open to the idea of
> creating an official squad for this work, but I'm not sure if it's
> needed or not.
+1 !
--
Giulio Fidente
GPG KEY: 08D733BA
More information about the OpenStack-dev
mailing list
{kind=link}