[openstack-dev] [neutron] Risk prediction model for OpenStack
林泽燕
linzeyan at pku.edu.cn
Thu Apr 6 03:22:56 UTC 2017
Hi Kevin,
I believe that the code ownership can reflect the module size in some way. The code ownership is small, which means a lot of commits made by a group of contributors, and thus the module might be quite large.
And I think the amount of bugs might be used to identify the risky files for developers and managers and could act as an indicator of workload needed to improve the quality of the file, thus our develop team can estimate the workload on each file and adjust the work priority.
I wonder if I have made it clear. Thank you for your attention.
Zoey Lin
-----原始邮件-----
发件人:"Kevin Benton" <kevin at benton.pub>
发送时间:2017-04-05 22:17:08 (星期三)
收件人: "OpenStack Development Mailing List (not for usage questions)" <openstack-dev at lists.openstack.org>
抄送:
主题: Re: [openstack-dev] [neutron] Risk prediction model for OpenStack
Thanks for this analysis. So one thing that jumps out at me right away is the correlation of this with the module size. ovs_neutron_agent.py is one of the biggest modules (if not the biggest non-test module) in Neutron, so if you don't control for line count in the analysis, this one would come out on top even if it had the same code quality (bugs per line) as other modules. How do you deal with module size?
Cheers,
Kevin Benton
On Tue, Apr 4, 2017 at 11:01 PM, 林泽燕 <linzeyan at pku.edu.cn> wrote:
Dear everyone,
My name is Zoey Lin, majored in Computer Science, Peking University, China. I’m a candidate of Master Degree. Recently I'm making a research on OpenStack about the contribution composition of a code file, to predict the potential amount of defect that the file would have in the later development stage of a release.
I wonder if I could show you my study, including some metrics for the prediction model and a visualization tool. I would appreciate it if you could share your opinions or give some advices, which would really, really help me a lot. Thank you so much for your kindness. :)
First of all, I would give a brief introduction to my study. I analyzed and designed some metrics to describe the contribution composition of a code file, and then use these metrics to train a model to predict the amount of bug that a file would have as a risk value in the later development stage of a release, using the historical commit log data of the former development stage. The model showed a good performance. I also developed a tool to visualize the metrics and the potential risk value, which we believe could help developers and project managers being aware of the current situation and risk of the code file. We expect that project managers could estimate the workload, adjust the personnel assignment and locate the development problems based on the information of the tool and finally could reduce the risk and improve the quality of the project efficiently in some way.
Then, I would introduce two main metrics of my model.
1. code ownership of files and developers:
Code ownership shows the number of engineers contributing to a source code artifact and the relative proportion of their contributions. The code ownership of a file refers to the proportion of ownership for the contributor with the highest proportion of ownership, which could indicate that whether there is one developer who “owns” the file and has a high level of expertise, who can act as a single point of contact for others who need to use the component, need changes to it, or just have questions about it. Minor developer refers to developer whose code ownership is lower than 5%. Previous literatures have proven that code ownership and amount of minor developer strongly correlate with code defects.
2. contribution diversity of the file:
We measured the uncertainty in a code file's contributions (or the diversity of sources of contributions) in a given month using the Teachman/Shannon entropy index, a commonly used diversity measure in many scientific disciplines.
H(x) = E[I(xi)] = E[ log(2,1/p(xi)) ] = -∑p(xi)log(2,p(xi)) (i=1,2,..n),
p(xi) is the code ownership of developer xi, I(xi) means the information we need to judge if a contribution belongs to developer xi. H(x) ranges between 0, when all the contribution of the file belong to one developer in a release, and log(2, N), when N developers contribute equally (i.e., pi = 1/N) to the file. The larger H(x) is, the more diverse the contribution of the file is.
We assume that the more diverse the contribution, the more bugs the code file would have in this release. And We have proven that there is a significant positive correlation between the contribution diversity and the amount of defect of the file.
Next, I would give some intuitive displays and analysis about these metrics. We assume that it is Feb.2016 now.
This is part of the Release Page. We offer some basic information and the potential amount of bug we predict about the active code files in this release. The pie shows us the risk distribution of the potential risky files, which could help managers estimating the following workload and decide which files to mainly focus on.
Then comes the File page. We take the file neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py as an example.
The model predicts that the file would have 44 defects in the following development stage of the release (and we check the real data, there are 40 defects in fact).
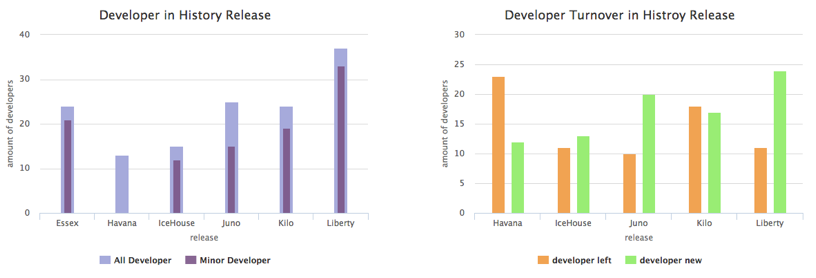
First, let's see how the contribution diversity and file code ownership developed in the past releases in the charts below. We can find that when the code ownership is small, which means there is not a developer who “own” the file, and the contribution diversity is large, which means the sources of the code of the file are diverse and the composition of code is complex, the amount of defect in that release would be large (for example, Liberty). In contrast, when the code ownership increase and the contribution diversity decrease (for example, Kilo), the amount of defect would be smaller. It shows that the amount of bug is affected by the code ownership and contribution diversity in some way, which have also been proven by my study.
And now, (shown in the green box above) the code ownership is 0.11 (quite small), and contribution diversity is 5.07 (quite large), we can predict that the amount of defect would be large, like Liberty.
After being aware of the potential risk of the file, we try to offer some information to help locate the problems.
1. In this release, we had just 3 major developers and 36 minor developers, and even the code ownership of major developer is small (0.11), it might result in the fact that, no one can guide the development of the file, and act as a point of contact for others. And large amount of minor developer might increase the contribution diversity. These would all result in high risk of defects.
2. We can see from the charts in the purple box above. In this release, 24 developers left the development of this file (they made contributions in last release but not this one). Developers leaving a code file deprive the file of the knowledge of the decisions they have made. Previous research shows that the survivors and newcomers maintaining abandoned code have reduced productivity and are more likely to make mistakes. And the file had 26 newcomers, who might not be familiar with the design and framework of the code file, the new contributions they made might conflict with the others and thus might bring defects. Therefore, I think we should pay attention to these contributions to reduce the risk of defects.
3. We can also see how the developers' contribution composition develops by month. In these charts, we can specific which month had unreasonable work distribution, and then check the code contribution in that month. In this release, we can suppose that the contribution made in Nov.2015 might bring some defects, and we should pay attention to these contributions to reduce the defect risk.
Ok, that are some examples of the information we could get from the visualization tool. And I hope to know what you think about them on the following three questions, which would give me great help on my research:
1. Do you think the metrics information I offered in the tool are useful for developers and project managers in some way?
In particular, could the code ownership be used to identify the experts of the file and how would it help in practice?And do you think that files with high code ownership would result in higher code quality and fewer failures?
Do you think the contribution diversity could act as an indicator for high risk of lower code quality of the file in some way and why? And what would it mean in practice when the contribution diversity of a file changes a lot?
Do you agree that when contributors left the project, their code would be hard to be maintained by others, and contributions made by newcomers would be more likely to bring bugs to the files? So would it help by knowing how many people left the project and how many people are newcomers to the projects and who are them? If yes, how would it help in practice?
2. Do you think the analysis I made about the example (paragraph in blue font) make sense? And what else information you can get from the charts and how can they help? Or what else information you expect to get from the visualization tool?
3. Do you think it make sense to predict the potential amount of bug that need to fix in the later development stage of a release by analyzing the metrics of the former development stage of the release?
Again, I would appreciate it a lot if you could share your opinions. And thank you so much for your time.
Looking forward to your reply. Wish you all have a good day.
Best regards!
——————————
Zeyan Lin
Department of Computer Science
School of Electronics Engineering & Computer Science
Peking University
Beijing 100871, China
E-mail:linzeyan at pku.edu.cn
__________________________________________________________________________
OpenStack Development Mailing List (not for usage questions)
Unsubscribe: OpenStack-dev-request at lists.openstack.org?subject:unsubscribe
http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev
Best regards!
——————————
Zeyan Lin
Department of Computer Science
School of Electronics Engineering & Computer Science
Peking University
Beijing 100871, China
E-mail:linzeyan at pku.edu.cn
-------------- next part --------------
An HTML attachment was scrubbed...
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0001.html>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 1release.png
Type: image/png
Size: 204938 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0006.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 2top.png
Type: image/png
Size: 69946 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0007.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 3history.png
Type: image/png
Size: 89872 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0008.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 4developer1.png
Type: image/png
Size: 90935 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0009.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 5developer2.png
Type: image/png
Size: 44009 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0010.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: 6month.png
Type: image/png
Size: 135296 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20170406/abc54d32/attachment-0011.png>
More information about the OpenStack-dev
mailing list
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}