[openstack-dev] [Neutron][LBaaS] Proposal for model change
Stephen Balukoff
sbalukoff at bluebox.net
Tue Feb 11 00:45:39 UTC 2014
Howdy folks!
Let me start by apologizing for the length of this e-mail. Over the past
several months I’ve been trying to get up to date on the current status of
LBaaS in the OpenStack community, and from what I can tell, it looks like
Neutron LBaaS is the project that is both the one most open to new
contributors, as well as the one seeing the most active development at this
time. I have a proposal I want to discuss, and I understand that this
mailing list is probably the best place to attempt a discussion of Neutron
LBaaS, where it’s at, and where it’s going. If I should be posting this
elsewhere, please excuse my newbishness and point me in the right direction!
Background
The company I work for has developed its own cloud operating system over
the past several years. Most recently, like many organizations, we’ve been
making a big shift toward OpenStack and are attempting to both mold our
current offerings to work with this platform, and contribute improvements
to OpenStack as best we’re able. I am on the team that built two successive
versions of the load balancer product (in addition to having experience
with F5 BIG-IPs) which works in our cloud operating system environment.
It’s basically a software load balancer appliance solution utilizing
stunnel and haproxy at its core, but with control, automation, and API
built in-house with the goal of meeting the 90% use case of our customer
base (which tend to be web applications of some kind).
Neutron LBaaS today
Looking at the status of Neutron LBaaS right now, as well as the direction
and rate of progress on feature improvements (as discussed in the weekly
IRC meetings), it seems like Neutron LBaaS accomplishes several features of
one particular competitor’s load balancer product, but still falls short of
offering a product able to meet 90% of consumer’s needs, let alone a
significant number of the basic features almost every commercial load
balancer appliance is able to do at this point. (See the bulleted list
below.) I know there’s been talk of adding functionality to the Neutron
LBaaS solution so that drivers for individual commercial products can
extend the API as they see fit. While this might be ultimately necessary to
expose certain extremely useful features of these products, I think there’s
a more fundamental problem with the Neutron LBaaS right now: Specifically,
I think the model we’re using here is too simplistic to effectively support
more advanced load balancer features without significant (and annoying)
hack-ish workarounds for deficiencies in the model.
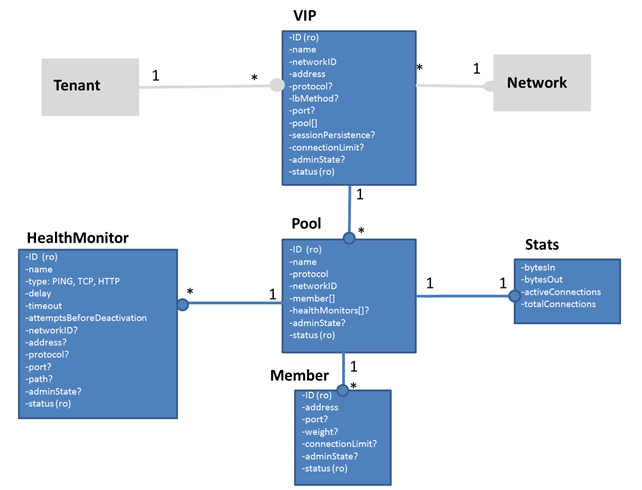
I should mention that I’m going off this model, as it appears to correspond
with Neutron LBaaS as it exists in Havana (and I think Icehouse-- since
Icehouse is unlikely to get the SSL offloading and L7 features currently
under development), and while a new ‘loadbalancer’ entity has been
proposed, I’ve not yet seen an updated data model diagram which plugs this
in anywhere:
https://wiki.openstack.org/w/images/e/e1/LBaaS_Core_Resource_Model_Proposal.png
Given the above model, it looks like significant changes will need to
happen to support the following features in a “non-hackish” kind of way.
These features are certainly among the ‘essential’ features our production
customers use in other load balancer products, all of which seem like good
ideas to eventually add to OpenStack’s load balancer functionality:
-
Multiple pools per VIP (ie. “layer 7” support)
-
Multiple load balanced services per floating IP
-
SSL offloading (with SNI support)
-
High Availability
-
Automated provisioning of load balancer devices
-
Automated scaling of load-balancer services
New Model Proposal
So, having already solved this problem twice for our legacy cloud operating
system, I’d like to propose a model change which will ease in the addition
of the above features when they eventually get added. These models are
based closely on our Blocks Load Balancer version 2 (BLBv2) product, which,
again, is really just a software load balancer appliance based on stunnel +
haproxy (with our own glue added). I’ll attach these models to this e-mail
(and will happily provide the .dot files I used to generate these graphs to
anyone who wants them -- I like diagrams whose format plays nicely with
revision control systems like git).
The first model closely resembles what we do today with BLBv2. Significant
differences being that we like the use of cascading attributes (which
simplifies provisioning of new pools, pool members, etc. as they inherit
attributes from less-specific contexts), and we never saw the need to
separate out “stats” and “health monitoring” to their own data model
representations because these tend to be closely bound to front-ends or
back-ends (respectively). Also note that I realize it’s possible for
certain attributes (eg. member IP) to be gleaned from Nova. This might help
from a security perspective (ie. a tenant can only add nodes that are part
of their cluster, rather than any IP arbitrarily). But I also realize that
sometimes it’s advantageous to add “members” to a pool that aren’t actually
part of a given OpenStack cluster. Also, I don’t know how tightly we want
Neutron LBaaS to be coupled with Nova in this case. I think this is worth a
discussion, in any case.
The second model more closely resembles an enhancement of the current
Neutron LBaaS model, including the (IMO unnecessary) data models
representing the healthmonitor and stats entities, and no cascading
attributes.
In both models, I’ve split up the current Neutron LBaaS concept of a “VIP”
in the current model into “instance” and “listener.” “Instance” in this
case is essentially similar to a floating IP (and in an HA configuration,
actually would be a floating IP, though not in the typical “Neutron
floating IP” sense). It’s an IP address assigned to a tenant (internal or
external) on which they can set up multiple listening services. The
“listener” is one such listening service (in the case of our appliance, a
single haproxy or stunnel instance bound to a given TCP port).
Benefits of a new model
If we were to adopt either of these data models, this would enable us to
eventually support the following feature sets, in the following ways (for
example):
SSL offloading (with SNI support)
This should mostly be self-evident from the model, but in any case, a TLS
certificate should be associated with a listener. The
tls_certificate_hostname table is just a list of all the hostnames for
which a given SSL certificate is valid (CN plus all x509 subject
alternative names). Technically, this can be easily derived from the
certificate itself on the fly, but in our code we found we were referring
to this list in enough places it was simpler to enumerate it whenever a
certificate was imported.
SNI support is accomplished by associating multiple certificates to a given
listener and marking one as the ‘default’. (Current implementations of
stunnel do SNI just fine, including multiple wildcard certificates.) If
you’re a load balancer appliance vendor that can’t do SNI, then just using
the default cert in this model and ignoring any others probably makes sense.
Multiple pools per VIP
This is accomplished, in the haproxy world, through the use of ACLs (hence
the ACL join table). Note that I’ve not seen any discussion as of yet
regarding what kinds of layer-7 functionality Neutron LBaaS ought to
support-- that is, what is a minimally viable feature set here that both
customers are asking for and that vendors can support. In our customer
base, we have found that the following kinds of acls are the ones most
often used:
-
ACL based on server hostname (eg. “api.example.com goes to one pool,
www.example.com goes to another)
-
ACL based on URL path prefix (eg. URLs starting with
“/api<http://www.example.com/api>”
go to one pool, all others go to another)
-
ACL based on client IP or network range
-
ACL based on cookie
In any case, more discussion needs to happen in general about this as we
add L7 support to Neutron LBaaS, whether or not y’all like my model change
proposal.
Multiple load balanced services per floating IP
Obvious use case is HTTP and HTTPS listeners on the same IP. Hopefully this
is clear how this is now accomplished by splitting up “VIP” into “instance”
and “listener” entities.
High Availability
This is where the “cluster” concept of the model comes into play. A cluster
in this case indicates one or more “load balancer” objects which carry
similar configuration for balancing all the instances and listeners defined
and assigned to it. If the cluster_model is “active-standby” then the
presumption here is that you’ve got two load balancer entities (which could
be software appliances or vendor appliances) which are configured to act as
a highly available pair of load balancers.
Note that non-HA topologies also work fine with this model. In this case,
the cluster would have only one load balancer associated with it.
(Full disclosure: In our environment, at the present time we operate our
BLBv2 boxes exclusively in an active-standby HA configuration, where the
cluster IP addresses (both IPv4 and IPv6) are floating IPs that the two
nodes keep alive using corosync and pacemaker. I think we can accomplish
the same thing with a simpler tool like ucarp. We also exclusively use
layer-3 routing to route “instance” addresses to the right cluster’s
ha_ip_address. I think this is an as of yet unsolved “routed mode” version
of load balancing that I’ve seen discussed around Neutron LBaaS.)
Also note that although we don’t do this with BLBv2 right now, it should be
possible to set up an n-node active-active load balancer cluster by having
a flow-based router that lives “above” the load balancers in a given
network topology, and is configured to split flows between the load
balancers for incoming TCP connections. In theory, this makes for being
able to scale load balancer capacity “infinitely” horizontally, so long as
your flow-based router can keep up, and as long as you’ve got network and
compute capacity in your pools to keep up. This is extremely important for
SSL offloading (as I’ll talk about later). And given the discussions of
distributed routing going on within the Neutron project as a whole, sounds
like the flow-based router might eventually also scale well horizontally.
Automated provisioning of load balancer devices
Since load balancers are an entity in this model, it should be possible for
a given driver to spawn a new load balancer, populate it with the right
configuration, then associate it with a given cluster.
It should also be possible for a cloud administrator to pre-provision a
given cluster with a given vendor’s load balancer appliances, which can
then be used by tenants for deploying instances and listeners.
Automated scaling of load-balancer services
I talked about horizontal scaling of load balancers above under “High
Availability,” but, at least in the case of a software appliance, vertical
scaling should also be possible in an active-standby cluster_model by
killing the standby node, spawning a new, larger one, pushing
instance/listener configuration to it, flip-flopping the active/standby
role between the two nodes, and then killing and respawning the remaining
node in the same way. Scale-downs should be doable the same way.
Backward compatibility with old model workflows
I realize that, especially if the old model has seen wide-scale adoption,
it’s probably going to be necessary to have a tenant workflow which is
backward compatible with the old model. So, let me illustrate in pseudo
code, one way of supporting this with the new model I’ve proposed. I’m
going off the tenant workflow described here:
1.
Create the load balancer pool
2.
Create a health monitor for the pool and associate it with the pool
3.
Add members (back-end nodes) to the pool
4.
Create a VIP associated with the pool.
5.
(Optional) Create a floating IP and point it at the VIP for the pool.
So, using the proposed model:
1. Client issues request to create load balancer pool
* Agent creates pool object, sets legacy_network attribute to network_id
requested in client API command
2. Create a health monitor for the pool and associate it with the pool
* Agent creates healthmonitor object and associates it with the pool. For
v1 model, agent sets appropriate monitor cascading attributes on pool
object.
3. Add members (back-end nodes) to the pool
* Agent creates member objects and associates them with the pool.
4. Create a VIP associated with the pool.
* Agent checks to see if cluster object already exists that tenant has
access to that also has access to the legacy_network set in the pool.
* If not, create cluster object, then spawn a virtual load balancer node.
Once the node is up, associate it with the cluster object.
* Agent creates instance object, assigns an IP to it corresponding to the
cluster’s network, associates it with the cluster
* Agent creates listener object, associates it with the instance object
* Agent creates ‘default’ acl object, associates it with both the listener
and the pool
* Agent pushes listener configuration to all load balancers in the cluster
5. (Optional) Create a floating IP and point it at the VIP for the pool.
* Client creates this in the usual way, as this operation is already
strictly out of the scope of the Neutron LBaaS functionality.
Beyond the above, I think it’s possible to create functional equivalents to
all the existing neutron load balancer API commands that work with the new
model I’m proposing.
Advanced workflow with proposed model
There’s actually quite a bit of flexibility here with how a given client
can go about provisioning load balancing services for a given cluster.
However, I would suggest the following workflow, if we’re not going to use
the legacy workflow:
1. OpenStack admin or Tenant creates a new cluster object, setting the
cluster_model. OpenStack admin can specify whether cluster is shared.
2. Depending on permissions, OpenStack admin or Tenant creates load
balancer object(s) and associates these with the cluster. In practice, only
OpenStack admins are likely to add proprietary vendor appliances. Tenants
may likely only be able to add virtual appliances (which are run as VMs in
the compute environment, typically).
3. Client creates instance, specifying the cluster_id it should belong to.
4. Client creates listener, specifying the instance_id it should belong to.
(Note at this point, for non-HTTPS services with haproxy at least, we know
enough that the service can already be taken live.) If client just wants
service to be a simple redirect, specify that in the listener attributes
and then do only the next step for HTTPS services:
5. For HTTPS services, client adds tls_certificate(s), specifying
listener_id they should belong to.
6. Client creates pool. For v1 model, client can set monitoring attributes
at this point (or associate these with the instance, listener, etc. Again,
there’s a lot of flexibility here.)
7. Client creates healthmonitor, specifying pool_id it should be associated
with.
8. Client creates 0 or more member(s), specifying pool_id they should be
associated with.
9. Client associates pool to listener(s), specifying ACL string (or
default) that should be used for L7 pool routing. First pool added to a
listener is implicitly default.
10. Repeat from step 6 for additional back-end pools.
11. Repeat from step 4 for additional services listening on the same IP.
12. Repeat from step 3 for additional services that should listen on
different IPs yet run on the same load balancer cluster.
A note on altering the above objects:
-
Adding or removing a load balancer from a cluster will usually require
an update to all existing (or remaining) load balancers within the cluster,
and specifically for all instances and listeners in the cluster. It may be
wise not to allow the cluster_model to be changed after the cluster is
created, as well. (Because switching from a HA configuration to a
single-node configuration on the fly requires a level of agility that is
problematic to reliably achieve.)
-
Of course any changes to any of the instances, listeners,
tls_certificates, pools, members, etc. all require any linked objects to
have updates pushed to the load balancers as well.
The case for software virtual appliance
You may notice that the model seems to inherently favor load balancer
topologies that use actual vendor appliances or software virtual
appliances, rather than the default haproxy method that ships readily with
Neutron LBaaS in its current form. (That is, the default driver where a
given “VIP” in this case ends up being an haproxy process that runs
directly on the Neutron server in a given openstack topology.) While the
models I’m proposing should still work just fine with this method, I do
tend to bias toward having the load balancing role live somewhere other
than core routing functionality because it’s both more secure and more
scalable. Specifically:
Security
In our experience, when a given customer’s web application cluster gets
attacked by malicious entities on the internet, the load balancers in the
cluster are the most commonly attacked components within the cluster. As
such, it makes sense to not double-up its role in the cluster topology with
any other role, if possible. One doesn’t want a compromised load balancer
to, for example, be able to alter the network topology of the tenant
network or disable the firewall protecting more vital components.
Also, having load balancing live somewhere separate from routing
functionality lends more flexible ways to add other security features to
the cluster (like, say, a web application firewall.)
Scalability
SSL offloading is the most CPU intensive task that most load balancers will
do. And while the openSSL library is fairly multi-threaded, there are
enough single-threaded “critical code” components within what it is doing
(eg. SSL cache access) that in our experience it might as well be limited
to a single core. Therefore, the upper limit on how many new connections
per second a given SSL termination process (eg. stunnel) can handle is
ultimately going to be limited by the clock speed of the processor. Even
with the hardware acceleration on modern Intel procs. As the strategy
within CPU manufacturing has been pushed by physical limitations to go with
more cores rather than faster clocks, and as the requirements for key
length are going to ever be increasing, this means that it’s going to
become more and more expensive to do SSL termination on a single node. Even
with better parallelization of the SSL functionality, at a certain point
the linux scheduler becomes the limiting factor as it churns through
thousands of context switches per second.
To give some context to this: In our experience, a non-SSL haproxy process
can handle several tens of thousands of new connections per second with the
right kernel tuning. But on current-generation processors, a single
stunnel process can handle only about 1200-1400 new connections per second
when using 1024-bit RSA keys (depreciated), and 200-300 new connections per
second using 2048-bit RSA keys (current standard), before becoming
CPU-bound. When 4096-bit keys become the standard, we can expect another 5x
decrease in performance. Turning keepalive on can help a lot, depending on
the web application we’re fronting. (That SSL handshake upon starting a new
connection is by far the most expensive part of this process.) But
ultimately, it should be clear the only real scaling strategy right now is
to go horizontal and have many more processes terminating client
connections.
So given the above, it seems to me the only real scaling strategy here must
be able to run a load balancing cluster across many physical machines.
Other Benefits of Appliance model
There are a couple other benefits that bear mentioning that the appliance
model has over the run-haproxy-on-the-nework-node model:
-
Clients are often not agnostic about what load balancer product they use
for various reasons. Even though this largely goes against the whole
philosophy of “cloud-like” behavior, I can see a need for clients to be
able to specify specific load balancers a given VIP gets deployed to.
-
In a distributed routing scenario, appliances fit into the topology
better than attempting to do, say, session management across several
network nodes.
-
The software virtual appliance model closely parallels the vendor
hardware appliance model-- meaning that if we were to adopt a software
virtual appliance model and (eventually) scrap the
haproxy-on-the-network-node model, we’ll have fewer code paths to test and
maintain.
Stuff missing from my proposed models
The following are not yet well defined in the model I’ve given, though most
of these should be able to be added with relatively minor model changes:
-
Stats model that automatically sends data to other OpenStack components
(like ceilometer)
-
Logging offload (though, again, this should be pretty trivial to add)
-
Other load balancing strategies/topologies than the ones I’ve mentioned
in this e-mail.
-
Discussion around the secure transmission of SSL private keys needs to
continue. In our environment, we use an SSL encrypted REST service
listening on the load balancer’s ip address which does both client and
server certificate verification, thereby handling both auth and encryption.
I understand discussions around this are already underway for how to handle
this in the current Neutron LBaaS environment. I see no reason why whatever
we figure out here wouldn’t directly translate to the models I’ve proposed.
-
Tenant network ID is conspicuously absent from my model at present,
though it’s somewhat implied with the IP address information that gets set
in the various objects. I’m guessing tenant network would apply at the
“cluster” level in my models, but need to understand more about how and
where it’s used in the current Neutron LBaaS data model before I can be
certain of that. Also, I would guess some discussion needs to happen around
the case of providers who use a vendor's appliance which may need to have
access to multiple tenant networks.
Next Steps for Me
I am fully aware that in the OpenStack community, code talks and vaporware
walks. My intent in writing this excessively long e-mail was to broach the
subject of a significant model change that I believe can really help us not
to paint ourselves into a corner when it comes to features that are
undoubtedly going to be desirable if not essential for OpenStack’s load
balancing functionality to have.
So, while we discuss this, in the mean time my intention is to concentrate
on creating the completely open-source software virtual appliance that I
think is glaringly absent from Neutron LBaaS right now, working through the
driver model presently in Neutron LBaaS. As far as I’m aware, nobody else
is working on this right now, so I don’t think I’d be duplicating effort
here. (If you are working on this-- let’s talk!) This problem will have to
be solved for the model I’ve proposed anyway.
Also, since we’ve essentially solved the software appliance problem twice
already, I don’t imagine it will take all that long to solve again, in the
grand scheme of things. (I would simply open-source the latest incarnation
of our “Blocks Load Balancer”, but there are a few components therein that
are very specific to our legacy cloud OS that I’ve not gotten definite
clearance on releasing. Besides, all of our glue is written in a
combination of perl, ruby, and shell -- and I understand with OpenStack
it’s python or the highway.)
So there we have it! I would very much appreciate your feedback on any of
the above!
Thanks,
Stephen
--
Stephen Balukoff
Blue Box Group, LLC
(800)613-4305 x807
-------------- next part --------------
An HTML attachment was scrubbed...
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20140210/8f1c51cc/attachment-0001.html>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: new-model-v1.png
Type: image/png
Size: 173054 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20140210/8f1c51cc/attachment-0002.png>
-------------- next part --------------
A non-text attachment was scrubbed...
Name: new-model-v2.png
Type: image/png
Size: 136349 bytes
Desc: not available
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20140210/8f1c51cc/attachment-0003.png>
More information about the OpenStack-dev
mailing list
{kind=link}
{kind=link}
{kind=link}