[openstack-dev] [Heat] A concrete proposal for Heat Providers
Tripp, Travis S
travis.tripp at hp.com
Thu May 2 17:39:35 UTC 2013
> -----Original Message-----
> From: Thomas Spatzier [mailto:thomas.spatzier at de.ibm.com]
> Sent: Thursday, May 02, 2013 1:25 AM
> To: OpenStack Development Mailing List
> Subject: Re: [openstack-dev] [Heat] A concrete proposal for Heat Providers
>
> Clint Byrum <clint at fewbar.com> wrote on 29.04.2013 19:50:22:
>
> > From: Clint Byrum <clint at fewbar.com>
> > To: openstack-dev <openstack-dev at lists.openstack.org>,
> > Date: 29.04.2013 19:51
> > Subject: Re: [openstack-dev] [Heat] A concrete proposal for Heat
> Providers
> >
> > Excerpts from Zane Bitter's message of 2013-04-26 10:41:25 -0700:
> > > On 26/04/13 09:39, Thomas Spatzier wrote:
> > > > So if I use multiple nested stacks with each one deploying a
> > > > couple of VMs, will I end up with the sum of VMs that all
> the
> > > > stacks create? Or will it be possible to, for example, please
> > > > Tomcat defined in one Stack on the same VM as MySQL defined in
> > > > another
> Stack? I
> > > > think it should be possible to have means for defining collocation
> > > > or anti-collocation kinds of constraints.
> > >
> > > Heat as it exists now manages resources that map more or less
> > > directly to objects you can manipulate with the OpenStack APIs. Nova
> > > Servers, Swift Buckets, Quantum Networks, &c. The software that runs
> > > on an instance is not modelled in the template; it's just data that
> > > is passed
>
> > > to Nova when a server is created.
> > >
> > > I'm struggling to understand why you would want Tomcat from one
> > > stack co-located with MySQL from another stack (which implies a
> > > completely different application)... isn't the popularity of
> > > virtualisation entirely due to people _not_ wanting to have to do
> > > that? Can you elaborate on the use case a little more here?
> > >
> >
> > If we have a flavor that fits every use case, then yes, combining work
> > loads into VMs is somewhat counter-productive.
> >
> > However, consider the baremetal use case, where we may have a rack of
> > 40 identical servers, all powerful enough to handle the most demanding
> > of our applications, but also far too powerful to handle one of them.
> > I am actually running into this right now while trying to write CFN
> > templates for OpenStack on OpenStack.
> >
> > The Heat API services, for instance, are very lightweight. But
> > keystone can be very taxing on memory and CPU. I'd like to be able to
> > group all of the light weight services together inside one "server".
> > At the same time, I may want to be able to split them out.
> >
> > This applies to the virt use case as well. As has already been stated,
> > there are optimization reasons to run two apps on the same VM. There
> > is also a cost issue. A smaller testing cloud may not be able to give
> > developers all of the VMs that production requires, and so people will
> > want to co-locate things together.
>
> So seems like we have agreeement that being able to influence placement is a
> useful feature. From my perspective, the ultimate goal would be to be able to
> define re-usable building blocks as modules (e.g. nested stacks - or call it
> differntly in the new DSL) that can be used in multiple scenarios. Then it should
> be possible to either consolidate on one server, or end of with a number of
> servers.
> What also could make sense is to make this environment-dependent, e.g. all on
> one server in development, but all on seperate servers in production.
>
> >
> > So I think the message here is that there are two concepts that should
> > be expressable separately:
> >
> > * I have app X, which needs informational bits a,b, and c, from other
> > parts of my stack.
> >
> > * I want to run app X on a compute resource with properties y and z.
> >
> > So, it would be useful if the DSL is able to express things things
> > separately.
>
> I did not fully get the two points above. Can you elaborate more or give an
> example?
>
> >
> > As another data point, the juju project still struggles with this
> concept,
> > and it has been a real sticking point for a lot of users to not be
> > able to assemble their apps separate from their resources.
> >
[Tripp, Travis S]
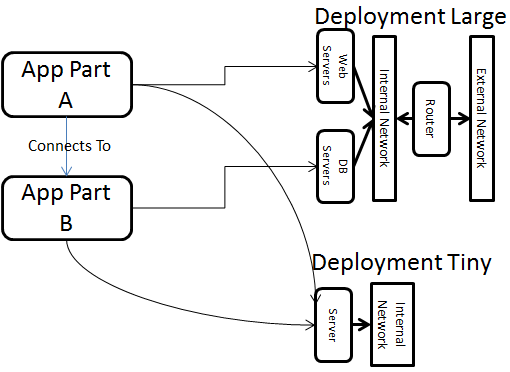
I agree with Clint. This essentially boils down to being able to describe my application(s) and how to deploy them separately from the resources where I want to deploy them. Then based on the target environment, I have a way to deploy my app to different resources without having to modify / copy paste my app model everywhere. In TOSCA terms, this is what the "relationship" concept provides. For example, I can design my application in one template and infrastructure(s) in another template. Then I essentially can have different deployments where I use the relationship to establish a source and a target for these relationship (App part A is associated to Infra part X). I just spoke with Thomas Spatzier and I think he is going to provide a simplified JSON or YAML representation of this concept.
I attached a quick diagram to illustrate the scenario.
-------------- next part --------------
A non-text attachment was scrubbed...
Name: RedeployableAppParts.PNG
Type: image/png
Size: 18745 bytes
Desc: RedeployableAppParts.PNG
URL: <http://lists.openstack.org/pipermail/openstack-dev/attachments/20130502/2e83072e/attachment.png>
More information about the OpenStack-dev
mailing list
{kind=link}